About us¶
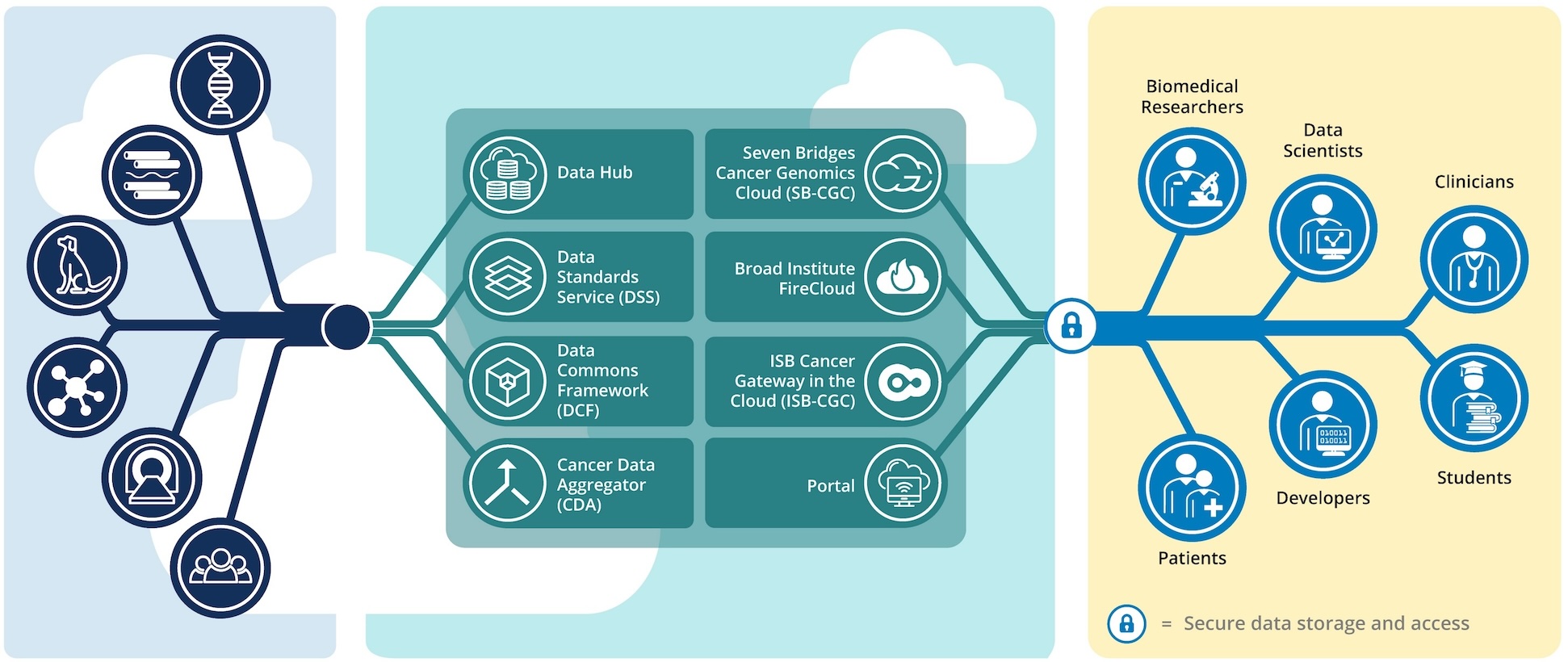
The Cancer Data Aggregator is a service of the National Cancer Institutes' (NCI) Cancer Research Data Commons. We pull metadata for thousands of studies hosted at multiple data repositories across NCI, and make it available for search from a single tool so researchers can more easily find and reuse existing cancer research data. In between pulling and publishing, we thoroughly clean, harmonize, and cross-reference the metadata so you can easily do things like find subjects that have participated in multiple studies, discover data from a disease that was originally described in different ways at each repository, and compile all the data from your favorite program such as CPTAC - no matter where it ended up.
To learn more about how we make metadata ready for search, head to our about our data page.
To learn more about how to access and work with data you find using CDA, visit the CRDC Cloud Resources page
About the Cancer Research Data Commons¶
The Cancer Research Data Commons (CRDC) is a cloud-based data science infrastructure that provides secure access to a large, comprehensive, and expanding collection of cancer research data. Users can explore and use analytical and visualization tools for data analysis in the cloud.
Our team¶
-

Arthur Brady Data wrangling & Developer
-

Amanda Charbonneau Testing & Directing

Tanner Coon Developer

David Pot Principal Investigator
Alumni¶

Bing-Xing Huo Principal Investigator - Broad

Finny Thomas Developer

Surya Saha Project Manager - Velsera

Jack DiGiovanna Principal Investigator - Velsera
-

Rachel Kutner Developer & Project Management
-

Kat Thayer Project Management
-

Alex Baumann Principal Investigator - Broad
Funding¶
This project has been funded in whole or in part with Federal funds from the National Cancer Institute, National Institutes of Health, Task Order No. 17X053 under Contract No. HHSN261200800001E